Security researchers have discovered a serious flaw in LangChain Core that could be exploited by malicious users to access confidential secrets by manipulating LLM behavior through prompt injection and deserialization of unsafe objects. LangChain Core (langchain-core) is an important foundational Python package in the LangChain ecosystem that supplies the necessary components for developers to build applications powered by LLMs.
Because of its importance, even small flaws in this component could affect everything else that makes use of the LangChain ecosystem. The issue is designated CVE-2025-68664 with a CVSS score of 9.3 and was first reported on 4 December 2025 by security researcher Yarden Porat, who has referred to it as the LangGrinch.
Why it Happened
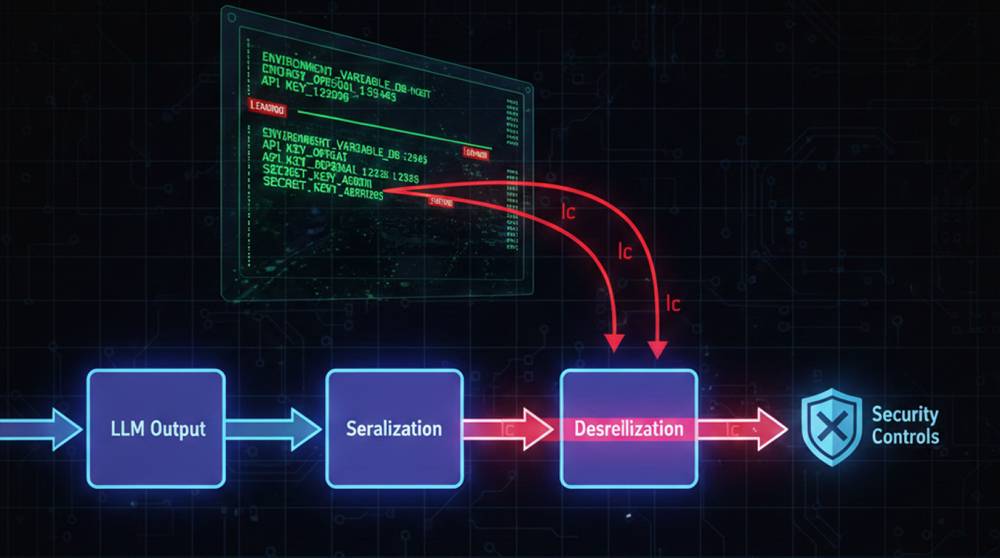
This vulnerability is a result of the changes made to how LangChain processes serialized objects. Both the dumps() and dumpd() methods do not adequately escape user-controllable dictionaries containing a unique internal key (lc) when they are being serialized.
The internal key (lc) serves to distinguish between serialized LangChain objects in the framework. Therefore, if a user is using untrusted input data that contains the lc key, the framework mistakenly interprets the untrusted input data as a legitimate internal object (according to its definition) and therefore, it will deserialize the untrusted input data; this leaves the serialized referenced object open to serialization injection. That means that an attacker can embed a crafted structure of objects into a LangChain workflow.
The consequences of an attacker getting a chance to work with serialized and deserialized items could result in some significant issues:
1. Exfiltration (theft) of secrets (environment variables) if secrets_from_env is enabled.
2. Creation (instantiation) of trusted internal classes from the pre-approved LangChain namespaces.
3. Retention (persistence) of prompt injection; the injected prompt content would influence future responses from an LLM.
4. In certain cases, additional exploitation, such as arbitrary code execution, due to the abuse of the Jinja2 template format.
The possibility of inserting these malicious entities into the application is compounded by the fact that they could be inserted into the application using innocuous field types such as metadata, additional_kwargs and response_metadata, all of which could be modified based on LLM output.
As noted by Porat, this is a classic example of working with the outputs of an LLM as though they are trusted (safe) and treating them in the same way as a user's input.
Fixes and Mitigations
LangChain has released patches that significantly tighten deserialization behavior:
1. A new allowlist-based control (allowed_objects) limits which classes can be loaded
2. Jinja2 templates are blocked by default
3. Automatic secret loading from environment variables is disabled by default
Affected Versions
Python (langchain-core)
1. >= 1.0.0, < 1.2.5 → fixed in 1.2.5
2. < 0.3.81 → fixed in 0.3.81
JavaScript / Node.js
A similar flaw exists in LangChain.js and is tracked as CVE-2025-68665 (CVSS 8.6):
1. @langchain/core >= 1.0.0, < 1.1.8 → fixed in 1.1.8
2. @langchain/core < 0.3.80 → fixed in 0.3.80
3. langchain >= 1.0.0, < 1.2.3 → fixed in 1.2.3
4. langchain < 0.3.37 → fixed in 0.3.37
The vulnerability indicates a significant security risk for AI models. Any time output from the language model is submitted directly into application code (including any piped code or loops of functions), there's a potential for that output to be a large point of entry into the application, or the "attack point" for attackers.
All organizations leveraging LangChain should immediately upgrade their versions and audit their serialization paths, while treating all LLM generated content as potentially malicious.
Source: The Hacker News